




I'm just a guy who likes to machine learn. I want the good ending not the bad one.
I work on AI alignment: steering, evals, and practical interpretability.
Links: wassname.org · Scholar · Hugging Face · LessWrong · Gists
Scalable, self-supervised alignment interventions. Ideally internal interventions, and driven by gradient. I'm always keen to discuss and brainstorm along these lines.
-
Weak 2 strong character steering (WIP, with Lyptus)

Can weight steering provide an interface for a weaker model to align a stronger model's moral character? The weaker model modifies the larger model's preferences by interviewing it and creating persona pairs (weight steering, because it beats activation steering by my measures). It can be iterative, can hopefully allow a large gap between weak and strong, and might even scale favourably with model size. Early draft is public now: a 9B teacher steering a 27B student toward "defer less to authority, care more", with no human labels. Draft · code
-
vGROUT (partial negative, code public) Quarantining reward hacking: can we use a hacking vector to route hacky gradients? Somewhat. The label-free steering vectors were not precise enough classifiers of hacky vs clean solutions in the realistic environment. The useful clue was initialization: signed-CorDA partially suppressed hacking by absorbing gradients into the hack-initialized quarantine adapter, dropping held-out hack from 0.759 to 0.218 in one 4B run. This is not a deployable operating point, but it is useful evidence because it uses synthetic pairs not labels, and strong labels may not be available for unknown reward hacks during frontier training. LW · code

Released along the way: steering-lite, lora-lite, steer-heal-love, tinymfv.
Ones I use and recommend:
| Repo | What it does |
|---|---|
| tinymfv | Tiny moral foundations vignettes; fast logprob measure of moral preference change. Still is a reliable and sensitive way to test your adapter or steering in ~10mins, I use this a lot and recommend it. |
| steering-lite | Hackable forward-hook activation steering; calibrated and tested. |
| lora-lite | Hackable single-file-per-variant LoRA built on forward hooks. Tested on GSM8K. |
| cwsteer | Contrastive weight steering: generate pairs, filter them, train one signed adapter, calibrate steering strength, bake for inference. |
| persona-steering-template-library | Persona/template validation for steering pairs; checks on-axis movement without obvious refusal, length, style, or assistant-tone confounds. |
| awesome-interpretability | Curated mechinterp + probing + tooling map. |
| adapters_as_hypotheses | Lit review: each LoRA-type adapter tells us something about how to look at transformer internals, some with causal evidence. |
Early drafts, contributions welcome:
| Repo | What it does |
|---|---|
| ml_debug | An attempt to uplift ML research taste in coding agents. Not working yet, but helps a bit. |
| pseudopy | A unicode+python type of pseudocode. |
-
AntiPaSTO Self-supervised steering of moral reasoning. Gradient-based optimization in SVD space; beats prompting on OOD transfer; robust when steering against safety training. arXiv:2601.07473 · LessWrong
-
S-space steering for eval-awareness control Replicated eval-awareness paper with novel S-space (singular value basis) steering; Hawthorne gap 1% vs prior work's 26% on Qwen3-32B. Apart Research Control hackathon 2026.

| Repo | What it does |
|---|---|
| open_pref_eval | Judge-free preference eval via logprobs. Converts Machiavelli, ETHICS, GENIES to fast logprob evals. |
| llm_ethics_leaderboard | Moral preference leaderboard; logprob rankings + permutation debiasing. Results site. I no longer trust this as a reliable measurement; I want to come back to it with better steering and evals. |
More datasets on Hugging Face.
Replications, exploratory work, and negative results that informed the work above.
| Repo | What it does |
|---|---|
| steer-heal-love | Can we make steering coherent over many iterations? Yes, with an RMSE-KL coherence constraint. Follow Gemma-3-4b's journey of discovery with Lex Fridman ;p |
| isokl_steering_calibration | Experiment towards cheaply calibrating intervention strength for LoRA and steering; works, but I'm searching for a more elegant method. 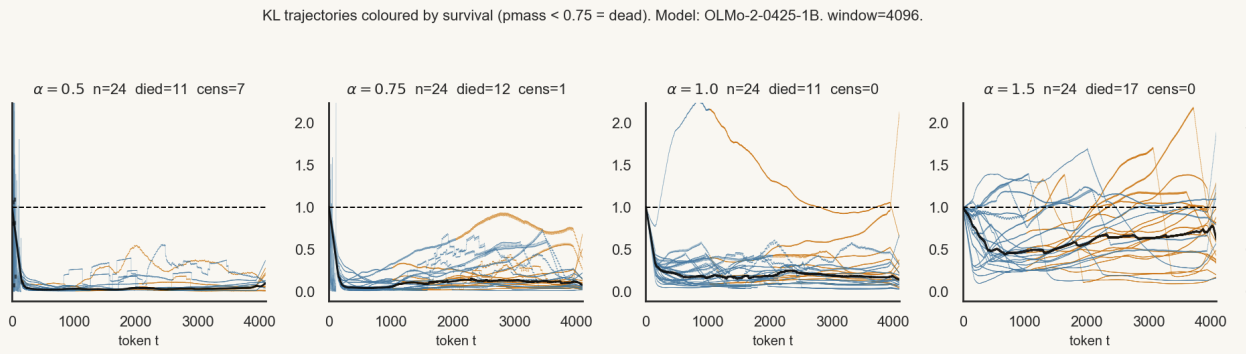 |
| Unsupervised-Elicitation | Replicated Anthropic's ICM paper; model self-reports labeling heuristics on TruthfulQA without supervision. LW note |
| coconut | Replicated Facebook's COCONUT + added SEQ-VCR loss. Found training is very slow (not emphasised by authors). WIP branch: adapter recursion in SVD space. |
| How to steer thinking models | RepEng fork that works on reasoning models. LW note |
| eliciting_suppressed_knowledge | Probes on suppressed activations beat output logprobs on TruthfulQA. Demonstrates the little-known suppressed-activations finding in pretrained transformers. |
| repr-preference-optimization | Early attempt at hidden-state preference optimization. Superseded by AntiPaSTO. |
| LoRA_are_lie_detectors | Adapters as end-to-end probes. Limitation: linear probes are not causal, so this didn't convince me. |
| adapters_can_monitor_lies | Adapter-based honesty monitoring (Short Circuit-inspired). Paused. |
Other ML work (world models, time series, misc)
World models
Time series & spatial
- attentive-neural-processes
- seq2seq-time
- np_vs_kriging
- rl-portfolio-management
- satellite_leak_detection
Misc