A melhor solução de reconhecimento de voz, tradução e dublagem multilíngue com IA 🚀











Voice-Pro é um aplicativo web de ponta que transforma a criação de conteúdo multimídia. Ele integra download de vídeos do YouTube, separação de voz, reconhecimento de fala, tradução e conversão de texto em fala (TTS) em uma única ferramenta poderosa, oferecendo uma solução ideal para criadores, pesquisadores e profissionais multilíngues.
- 🔊 Reconhecimento de fala de alto nível: Whisper, Faster-Whisper, Whisper-Timestamped, WhisperX
- 🎤 Clonagem de voz sem treinamento: F5-TTS, E2-TTS, CosyVoice
- 📢 Texto para fala multilíngue: Edge-TTS, kokoro (A versão paga inclui Azure TTS)
- 🎥 Processamento de YouTube e extração de áudio: yt-dlp
- 🌍 Tradução instantânea para mais de 100 idiomas: Deep-Translator (A versão paga inclui Azure Translator)
Como uma alternativa robusta ao ElevenLabs, o Voice-Pro capacita podcasters, desenvolvedores e criadores com soluções de voz avançadas.
- Devido ao trabalho de desenvolvimento do WeConnect, o desenvolvimento e as atualizações do Voice-Pro não são possíveis por enquanto.
- Tornamos todo o código do Voice-Pro de código aberto e completamente gratuito. O Voice-Pro agora pode ser distribuído e modificado livremente por qualquer pessoa.
- Funciona bem no Windows com GPU NVIDIA. O funcionamento no Mac e Linux não foi verificado.
- Por favor, deixe suas solicitações nas páginas de
ou
.
- Resolução de problemas: Na maioria dos casos, os problemas podem ser resolvidos excluindo a pasta
installer_filese, em seguida, executandoconfigure.batseguido porstart.bat.


version 3.2
- Estivemos focados no desenvolvimento do WeConnect nos últimos meses e não conseguimos gerenciar o Voice-Pro.
- Decidimos abrir o código do Voice-Pro.
- O Voice-Pro é completamente gratuito e suporta Windows, Mac, Linux.
- WeConnect é um aplicativo para intercâmbio cultural global.
- Conecte-se com pessoas de todo o mundo para intercâmbios culturais significativos, aprendizado de idiomas e amizades internacionais.





version 3.1
- 🪄 Suporte para modelos ajustados do F5-TTS
- 🌍 Idiomas suportados
English &
Chinese: SWivid/F5-TTS_v1
Finnish: AsmoKoskinen/F5-TTS_Finnish_Model
French: RASPIAUDIO/F5-French-MixedSpeakers-reduced
Hindi: SPRINGLab/F5-Hindi-24KHz
Italian: alien79/F5-TTS-italian
Japanese: Jmica/F5TTS/JA_21999120
Russian: hotstone228/F5-TTS-Russian
Spanish: jpgallegoar/F5-Spanish





Versão 3.0
- 🔥 A função AI Cover foi removida.
- 🚀 Suporte para m-bain/whisperX foi adicionado.
Versão 2.0
- 🐍 Construído com Python 3.10.15, Torch 2.5.1+cu124 e Gradio 5.14.0.
- 🆓 A versão de teste gratuita suporta mídias de até 60 segundos de duração.
- 🔥 A função AI Cover foi adicionada.
- 🎤 Suporte para CosyVoice e kokoro foi introduzido.
- ⏳ A primeira execução baixa CozyVoice2-0.5B (9GB), o que pode levar mais de uma hora dependendo da velocidade da rede.
- 🎧 Amostras de voz para clonagem serão atualizadas continuamente.
- 📝 spaCy foi adicionado para tradução e TTS naturais por sentença.
- ☁️ A versão por assinatura inclui o tradutor e TTS do Microsoft Azure.
- 🏪 A versão por assinatura oferece uso ilimitado (sem limite de 60 segundos) durante o período de assinatura e pode ser adquirida no
.
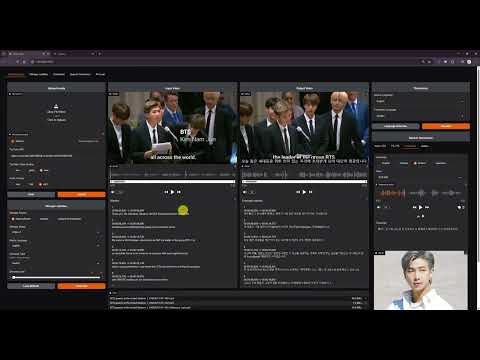

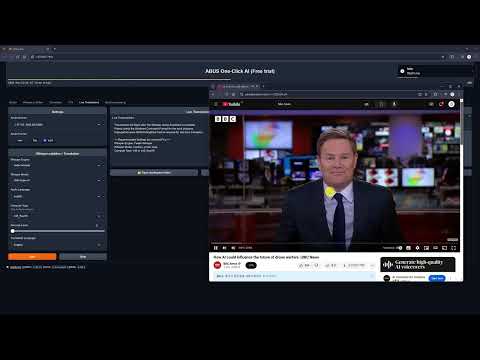






- Downloads de vídeos do YouTube e extração de áudio
- Separação de vozes com Demucs
- Suporta mais de 100 idiomas para reconhecimento e tradução de fala
- Fala para texto: Whisper, Faster-Whisper, Whisper-Timestamped, WhisperX
- Texto para fala:
- Edge-TTS: Mais de 100 idiomas, 400+ vozes
- E2-TTS, F5-TTS, CosyVoice: Clonagem sem treinamento prévio
- kokoro: Classificado como #2 na Arena TTS do HuggingFace
- Reconhecimento instantâneo de fala
- Tradução multilíngue em tempo real
- Entradas de áudio personalizáveis
- Centro integrado: Downloads do YouTube, remoção de ruído, legendas, tradução e TTS
- Suporta todos os formatos compatíveis com ffmpeg
- Opções de saída: WAV, FLAC, MP3
- Legendas e reconhecimento para mais de 100 idiomas
- TTS com ajustes de velocidade, volume e tom

- Foco em legendas: Mais de 90 idiomas
- Exibição de legendas integrada ao vídeo
- Destaque por palavra e opções de remoção de ruído
- Tradução para mais de 100 idiomas
- Suporte a arquivos de legendas (ASS, SSA, SRT, etc.)
- Reconhecimento e tradução de voz em tempo real

- Opções: Edge-TTS, F5-TTS, CosyVoice, kokoro
- Podcasts com vozes de celebridades e suporte multilíngue

- Por favor, solicite a voz que você deseja adicionar na página de Issues. Issues
English
 Andrew Bustamante |
 Andrew Huberman |
 Avi Loeb |
 Ben Shapiro |
 Brett Johnson |
 Brian Keating |
 Coffeezilla |
 Dan Carlin |
 David Buss |
 David Fravor |
 David Kipping |
 Dennis Whyte |
 Donald Hoffman |
 Donald Trump |
 Douglas Murray |
 Duncan Trussell |
 Elon Musk |
 Garry Nolan |
 Jack Barsky |
 James Sexton |
 Jeff Bezos |
 Joe Rogan |
 John Mearsheimer |
 Jordan Peterson |
 Kanye 'Ye' West |
 Mark Zuckerberg |
 Michael Levin |
 Michael Saylor |
 Michio Kaku |
 MrBeast |
 Nick Lane |
 Paul Rosolie |
 Ryan Graves |
 Sam Altman |
 Sam Harris |
 Stephen Wolfram |
 Tucker Carlson |
 Vitalik Buterin |
 Yuval Harari |
Chinese
 迪丽热巴 (Dílì Rèbā) |
 蔡依林 (Cài Yīlín) |
 吴亦凡 (Wú Yìfán) |
 李易峰 (Lǐ Yìfēng) |
 杨幂 (Yáng Mì) |
 赵丽颖 (Zhào Lìyǐng) |
Korean
 BTS 진 (Jin) |
 BTS RM |
 IU (아이유) |
 이병헌 |
 이정재 |
 유재석 |
Japanese
 綾瀬はるか (Ayase Haruka) |
- SO: Windows 10/11 (64 bits), Linux, Mac
- GPU: NVIDIA com suporte a CUDA 12.4 (recomendado)
- VRAM: 4 GB ou mais (8 GB+ preferível)
- RAM: 4 GB ou mais
- Armazenamento: Pelo menos 20 GB de espaço livre
- Internet: Obrigatória
Instale o Voice-Pro facilmente com configure.bat e start.bat (use configure.sh e start.sh no Mac/Linux).
- Baixe a versão mais recente em
(Source code (zip))
git clone https://github.com/abus-aikorea/voice-pro.git- 🚀 configure.bat
- Instala git, ffmpeg e CUDA (se usar GPU NVIDIA)
- Execute apenas uma vez; requer internet, pode levar mais de 1 hora
- Não feche a janela de comando
- 🚀 start.bat
- Inicia a interface web do Voice-Pro
- Na primeira execução, instala dependências (pode levar mais de 1 hora)
- Em caso de problemas, delete installer_files e execute novamente
- 🚀 update.bat: Atualiza o ambiente Python (mais rápido que reinstalar)
- Execute uninstall.bat ou delete a pasta (instalação portátil)
- Feche a janela de comando do Windows e execute start.bat novamente
- Abra o navegador manualmente e insira o endereço exibido na janela de comando (ex.: http://127.0.0.1:7870)
- Verifique o status da memória da GPU no Gerenciador de Tarefas do Windows - guia "Desempenho"
- Defina o nível de remoção de ruído para 0 ou 1 (o nível 2 requer pelo menos 8 GB de memória GPU)
- Configure o tipo de cálculo como "int" (o tipo "float" tem melhor qualidade, mas exige mais memória GPU)
- Modelos Whisper maiores tendem a melhorar a qualidade das legendas (large > medium > small > base > tiny), mas isso não é garantido
- Entre os tipos de cálculo, "float" oferece bom desempenho; "int" reduz o uso da GPU e aumenta a velocidade por meio de quantização do modelo, mas com perda de desempenho
- Aumentar o nível de remoção de ruído elimina mais sons de fundo e usa apenas a voz restante para reconhecimento, mas não garante sempre bons resultados
- Devido ao trabalho de desenvolvimento do WeConnect, não haverá atualizações do Voice-Pro por enquanto.
- Todo o código do Voice-Pro foi publicado como código aberto. Agora é completamente gratuito de usar.
- WeConnect é uma plataforma de comunicação para intercâmbio cultural global.
A tabela a seguir lista plataformas SaaS que suportam funcionalidades de legendagem, tradução e conversão de texto em fala (TTS/dublagem). Os custos foram calculados para o processamento de um vídeo em coreano de 60 minutos, incluindo geração de legendas, tradução para o inglês e dublagem em inglês, com base nos dados de preços mais recentes de 15 de abril de 2025.
| Plataforma | Legendagem | Tradução | TTS/Dublagem | Custo para Vídeo de 60 min (USD, aprox.) | Principais Características |
|---|---|---|---|---|---|
| Maestra | ✅ | ✅ | ✅ | $23.70 | Mais de 125 idiomas, legendas em tempo real, extração de palavras-chave SEO, teste gratuito de 15 min. |
| Kapwing | ✅ | ✅ | ✅ | $30~$40 (Plano Pro, por minuto) | Legendas por IA, tradução para mais de 100 idiomas, dublagem com sincronização labial automática, nível gratuito. |
| VEED.IO | ✅ | ✅ | ❌ | $24~$36 (Plano Pro, processamento parcial) | Legendas com 99,9% de precisão, legendas otimizadas para Instagram, editor intuitivo. |
| HappyScribe | ✅ | ✅ | ✅ | $36~$48 (Pagamento por uso) | Mais de 120 idiomas, opção de revisão profissional, seguro, transcrição de reuniões. |
| Sonix | ✅ | ✅ | ✅ | $30~$40 (Plano Standard) | Mais de 54 idiomas, 30 min de transcrição gratuita, integração com YouTube/Zoom. |
| Descript | ✅ | ✅ | ✅ | $36~$48 (Plano Criador) | Edição baseada em texto, Overdub TTS, remoção de palavras de preenchimento, 1 hora de transcrição gratuita. |
| AppTek | ✅ | ✅ | ✅ | Preços personalizados (Contato) | Focado em mídia, modelos personalizados, geração de metadados, Workbench baseado na nuvem. |
| Transkriptor | ✅ | ✅ | ❌ | $12~$18 (Pagamento por uso) | Mais de 100 idiomas, transcrição de links do YouTube, 99% de precisão, editor simples. |
- Maestra: Plano Premium ($158/mês, 1200 créditos). Vídeo de 60 min: 60 créditos (legendas) + 60 créditos (tradução) + 60 créditos (dublagem) = 180 créditos. Custo = (180/1200) * $158 = $23.70.
- Kapwing: Plano Pro (~$24/mês, minutos limitados). Estimado $0.50~$0.67/min para legendas+tradução+dublagem (com base em tendências de preços por minuto). Custo de 60 min: $30~$40. Confirmação de preços exatos necessária.
- VEED.IO: Plano Pro (~$24/mês). Legendas+tradução estimadas em $0.40~$0.60/min. Sem TTS, processamento parcial. Custo de 60 min: $24~$36. Confirme em veed.io.
- HappyScribe: Pagamento por uso (~$0.20/min transcrição, $0.20 tradução, $0.20 dublagem). Custo de 60 min: $36~$48 (assumindo serviços combinados). Confirme em happyscribe.com.
- Sonix: Plano Standard (~$10/hora transcrição, adicional para tradução/dublagem). Estimado $0.50~$0.67/min total. Custo de 60 min: $30~$40. Confirme em sonix.ai.
- Descript: Plano Criador (~$24/mês, horas limitadas). Estimado $0.60~$0.80/min para legendas+tradução+dublagem. Custo de 60 min: $36~$48. Confirme em descript.com.
- AppTek: Preços personalizados para empresas. Sem taxas públicas por minuto. Contate apptek.ai para cotações.
- Transkriptor: Pagamento por uso ($0.05~$0.10/min transcrição, similar para tradução). Sem TTS, processamento parcial. Custo de 60 min: $12~$18. Confirme em transkriptor.com.
- Custo para Vídeo de 60 min: Os custos são aproximados e assumem o processamento de um vídeo em coreano de 60 minutos para legendas, tradução para o inglês e dublagem em inglês (quando disponível). Plataformas sem TTS (ex.: VEED.IO, Transkriptor) refletem custos de processamento parcial.
- Suporte a Idiomas: A maioria das plataformas suporta coreano e inglês. Verifique a disponibilidade de idiomas específicos nos respectivos sites.
- Casos de Uso:
- Mídia/Entretenimento: AppTek, Maestra
- Redes Sociais: Kapwing, VEED.IO
- Podcasts/Entrevistas: Sonix, Descript
- E-learning/Conteúdo Global: Transkriptor, HappyScribe
- Atualizações de Preços: Os preços podem variar devido a mudanças nos planos ou promoções. Consulte os sites oficiais para detalhes atualizados.
- Para contribuições ou recomendações de casos de uso específicos, abra um issue ou envie um pull request neste repositório.
Olá, sou David da equipe Voice-Pro. Nossa equipe descobre as melhores tecnologias de IA do setor e as fornece para que qualquer pessoa possa usá-las de forma fácil e conveniente. Somos uma pequena startup na Coreia que existe há apenas um ano. Estamos trabalhando arduamente para ajudar você e outros criadores a produzir conteúdo excelente.
Sua avaliação de ⭐⭐⭐⭐⭐ seria muito apreciada, pois ajuda nossa empresa a crescer com você. Por favor, ajude a apoiar nossa pequena equipe.
Obrigado, Serviço de Atendimento ao Cliente ABUS
- Se você deseja participar e nos ajudar com este projeto, sinta-se à vontade para criar um Issues.
- Se algo der errado, envie um Pull requests para melhorar este projeto.
- Qualquer tipo de contribuição é bem-vindo.
- Para dúvidas relacionadas a compras, parcerias comerciais, ajustes técnicos, investimentos e outros assuntos, entre em contato conosco por e-mail (abus.aikorea@gmail.com).
- Se você gosta deste projeto, por favor, dê uma estrela a este repositório. Nós agradeceríamos muito. ⭐⭐⭐
- Você pode apoiar o Voice-Pro com uma doação aqui:

- Email: abus.aikorea@gmail.com
- Homepage (Korean): https://www.wctokyoseoul.com
- Demucs: https://github.com/facebookresearch/demucs
- yt-dlp: https://github.com/yt-dlp/yt-dlp
- gradio: https://github.com/gradio-app/gradio
- edge-TTS: https://github.com/rany2/edge-tts
- F5-TTS: https://github.com/SWivid/F5-TTS.git
- openai-whisper: https://github.com/openai/whisper
- faster-whisper: https://github.com/SYSTRAN/faster-whisper
- whisper-timestamped: https://github.com/linto-ai/whisper-timestamped
- whisperX: https://github.com/m-bain/whisperX
- CosyVoice: https://github.com/FunAudioLLM/CosyVoice
- kokoro: https://github.com/hexgrad/kokoro
- Deep-Translator: https://github.com/nidhaloff/deep-translator
- spaCy: https://github.com/explosion/spaCy
![]() por ABUS
por ABUS