Loss stagnates at 1.0 during training on custom dataset #776
Replies: 4 comments 10 replies
-
|
After training for 1000 epochs on a glow tts pre-trained model of 300,000 steps, I actually ran into the same issue. What else can I do? |
Beta Was this translation helpful? Give feedback.
-
|
how does the model sound? |
Beta Was this translation helpful? Give feedback.
-
|
Sure. Sounds pretty much the same as the previous one. Its like it understands my voice but not the text that corresponds to it https://drive.google.com/file/d/1ocgYkYz6UMpBKqnqzDoGPzx_Xv-YPv9K/view?usp=sharing |
Beta Was this translation helpful? Give feedback.
-
|
how long is your dataset in minutes? |
Beta Was this translation helpful? Give feedback.
-
|
and what is your source? It looks to me that the dataset is not suitable for TTS from what you give here. |
Beta Was this translation helpful? Give feedback.
-
|
The dataset is about 27 minutes in full. I recorded it myself. From what I understand, you can get a decent model from that amount of data if you finetune off another model, which is what I have done. What is wrong with it? |
Beta Was this translation helpful? Give feedback.
-
|
With that small dataset, you need to play with the hyperparameters a lot to find the best combination. It is a very small dataset even for fine-tuning without extra tricks. |
Beta Was this translation helpful? Give feedback.
-
|
I move it to the discussions as it does not conform to the issue template. |
Beta Was this translation helpful? Give feedback.
-
|
From what I've read and understand, the goal is to stop the encoder from training and just train the decoder on the new dataset. How to do that, I have no idea. I wonder if it's even possible only messing with the parameters, might have to mess with some code. If you have any ideas, let me know. I tried doing this using TacoTron2-DDC with some luck. I did about 1000 epochs on the dataset. The voice got clearer, but the overall quality didn't improve at all.
|
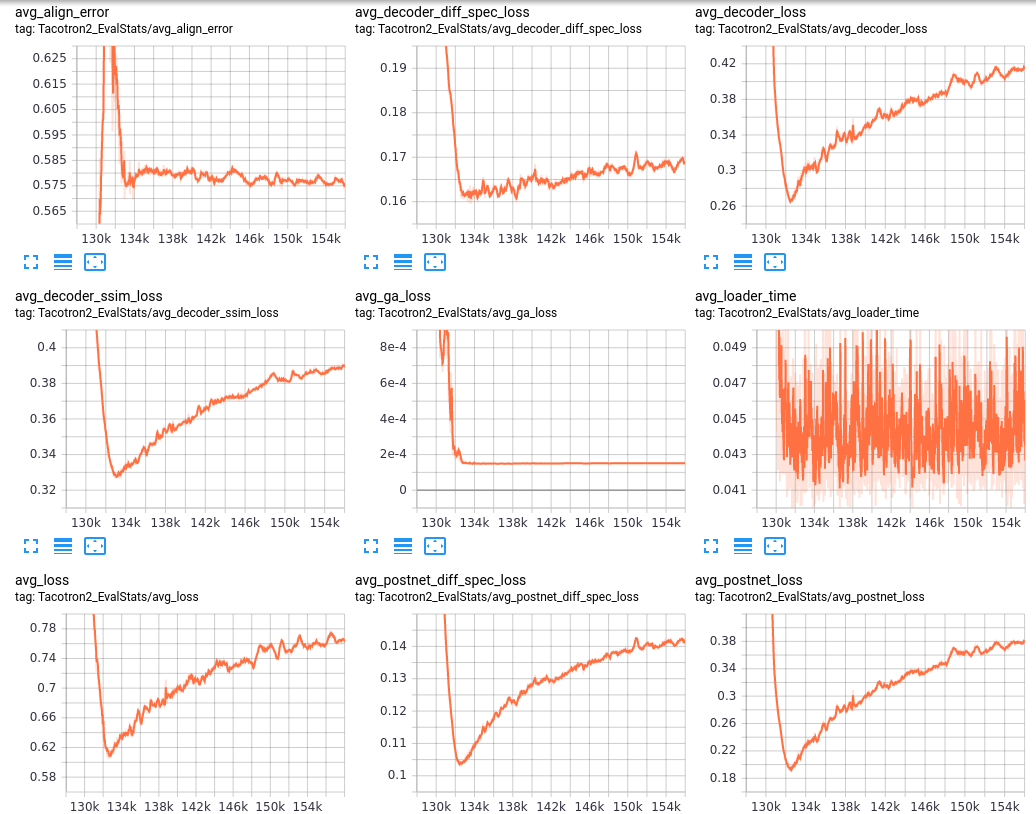
Beta Was this translation helpful? Give feedback.
-
|
There is no one recipe for fine-tuning. It totally depends on your dataset and you need to try different methods and parameters like the learning rate. There is yet no easy way to freeze certain layers, unfortunately. You should go into the code and do something like this https://discuss.pytorch.org/t/how-the-pytorch-freeze-network-in-some-layers-only-the-rest-of-the-training/7088 One interesting way is to add your dataset to the dataset that the model initially trained with but train the model in a multi-speaker setting. I saw some people trained good models by this approach but I've not tried myself. |
Beta Was this translation helpful? Give feedback.
-
|
I will 100% take a read into that link. I'm coming from the nvidia TacoTron2 repo so the parameters here are a little different. I am still trying to grasp what has changed. Does Coqui have a discord or something smaller to ask quick one off questions? Thank you for answering, I'm still trying to understand it all. |
Beta Was this translation helpful? Give feedback.
-
|
Welcome then !! There are links in the README for our Gitter room |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I have been finetuning off a model using Glow TTS on google colab. The training quickly dropped from to 1.0 loss and has increased for the past 1400 steps or so. I made sure to remove any noise or silence from my dataset of 300 samples, and used the analyze spectrograms notebook to check the configurations, so I am lost on what I need to do to make the loss drop further. Do I just need to continue to train?
Tensorboard results:

Configuration:

Dataset files:
https://drive.google.com/drive/folders/1OOIriahYvNPRnK3NMxzH0L1XF_cIGVuM?usp=sharing
Colab notebook:
https://colab.research.google.com/drive/1vYMd3FBpbpnFZeJlSZWCINdERAS_VUSr?usp=sharing
Beta Was this translation helpful? Give feedback.
All reactions